Traceback (most recent call last):
File “AutoPi.py”, line 28, in
schema = client.get(“https://api.autopi.io/auth/login/”)
File “C:\Users\ososc\AppData\Local\Programs\Python\Python37-32\lib\site-packages\coreapi\client.py”, line 136, in get
return transport.transition(link, decoders, force_codec=force_codec)
File “C:\Users\ososc\AppData\Local\Programs\Python\Python37-32\lib\site-packages\coreapi\transports\http.py”, line 386, in transition
raise exceptions.ErrorMessage(result)
coreapi.exceptions.ErrorMessage: <Error: 405 Method Not Allowed>
detail: “Method “GET” not allowed.”
What could be wrong? I managed to use requests.post() to retrieve some data. But it would be nice to get coreapi working, since it seems to be more user-friendly.
I appreciate this guide. It helped me get started on pulling data, but I am not able to find an exhaustive list of what “keys” (for example: https://api.autopi.io/logbook/storage/data/?type=primitive&key=coolant_temp&device_id=DEVICE_ID&start_utc=2018-05-02T15:17:51.389Z&end_utc=2018-05-02T15:35:07.360Z&interval=5m ) are possible to read data from. Specifically I am interested in getting the data from the accelerometer on my AutoPi, can you guide me through that?
Hi
Yeah, we are working on making that much more transparent.
To get the accelerometer, you specify the type “accelerometer”, instead of “primitive”, and then don’t specify the key.
That should give you the saved accelerometer values, but to get the device to save the accelerometer values, you also need to create a job that loags the accelerometer values.
To do that, you should go into jobs, and create a job that calls the “acc.xyz” function, with the returner set to “cloud”.
EDIT: You no longer need to manually log the accelerometer, it is part of the default logging now. Check out the advanced settings to see the settings for the accelerometer.
You can retrieve the trips via the API, and each trip includes a start time and an end time, which can be used to retrieve the raw data of the trips.
Check out the guide above, on how to retrieve the raw data.
@Malte
ok, i had download the postman, and succefull connected
so, now I want the request for new logger I had make, like SoC (for Ev car)
how to write it exactly same as that but for the SoC ?
I only need the result to send to mysql table, so 0 to 100 result. it is the raw data ?
Times are just for example, you want to change them
Also, I have no idea what field_type does. If it’s empty, I don’t get anything. If I put anything (“1” or “json” or “bla”) it spits out json formatted reply.
Strange
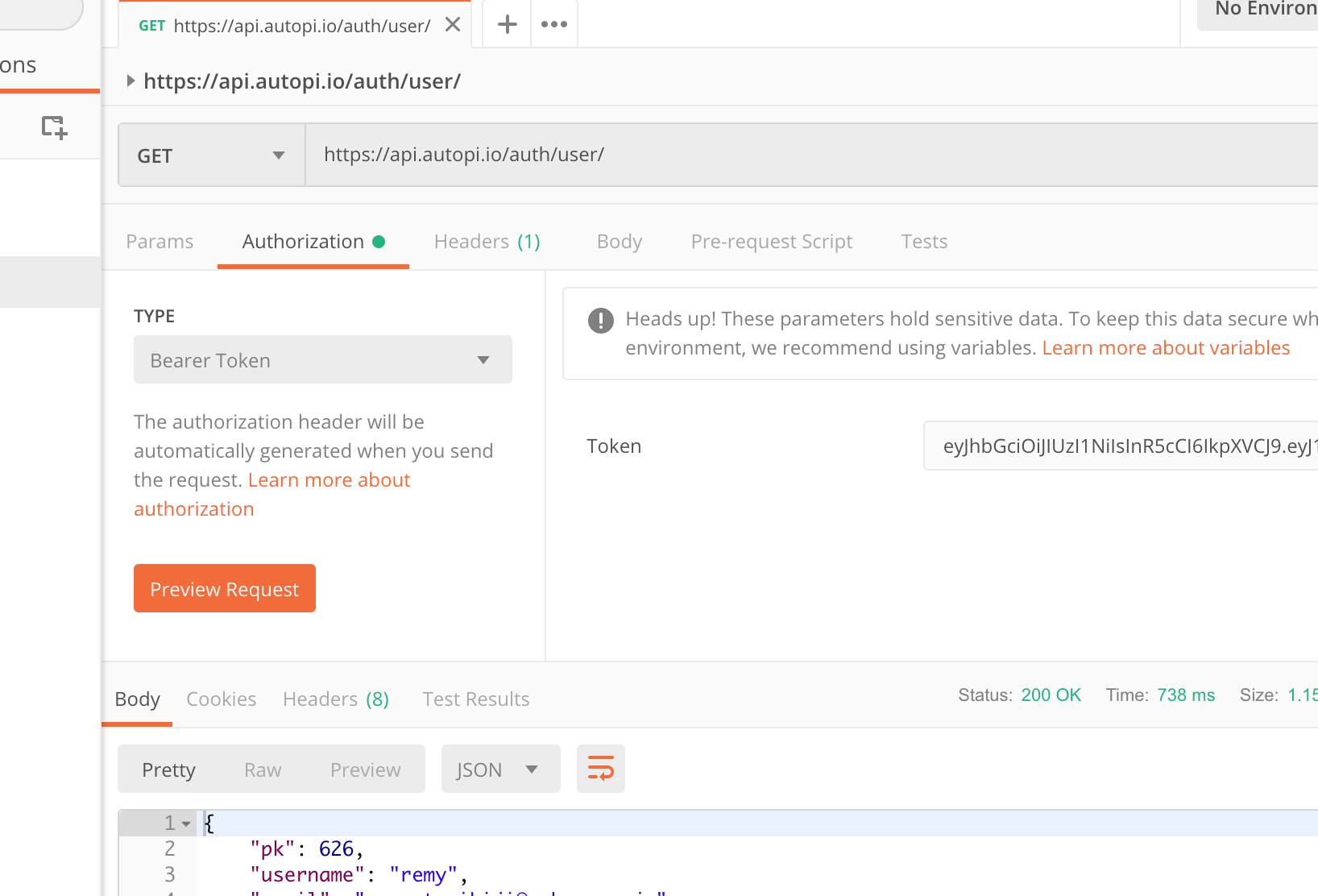
Make sure to also include bearer token in headers! You also get the device_id when requesting for a token.
You will get data at least 5 seconds late I think. You can put from_utc just a few minutes back and end_utc as current time.
I guess, I haven’t tried but should work?
thanks, it is working well. I just put my own token end own ID.
i had just change the seconde time value in 2now"
this is the screen shoot.
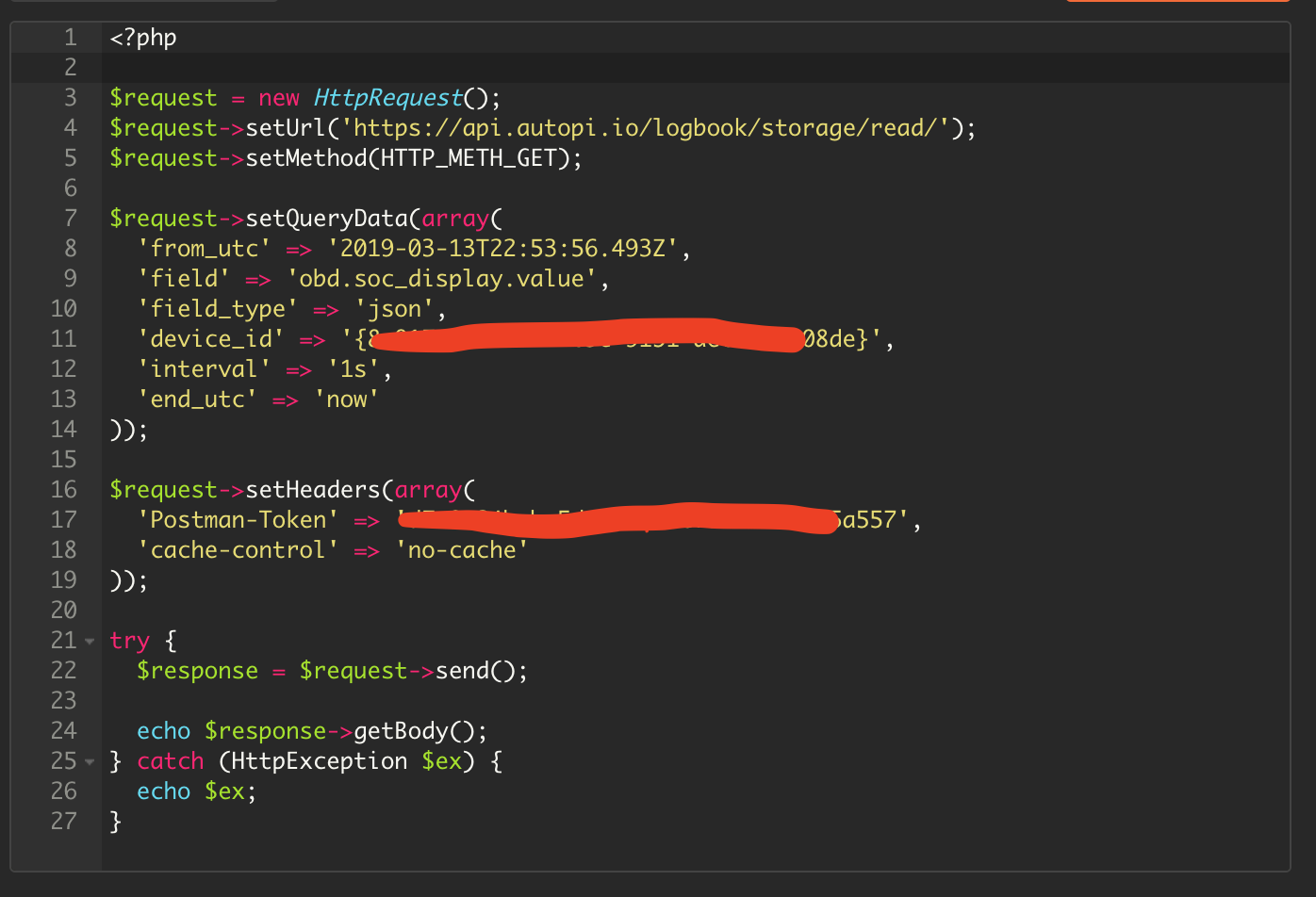
now I want to do the request from my web site, from a php or json page. then when I have the data, send the last one to mysql. (I have web app for the Kona I want to use )! but I dont know how to write same get as postman but in my web page.
@Remy_Tsuihiji I suspect your problem there is you’re sending “Postman-Token”, the one you want is “Authentication”, where the value should be “bearer my-api-key”.
Hi, I’m trying the login request but I’m getting a security error saying:
The page at ‘https://api.autopi.io/’ was loaded over HTTPS, but requested an insecure resource ‘http://backend01/auth/login/’. This request has been blocked; the content must be served over HTTPS.
Is it a problem on your side or am I doing something wrong here?
Hi, I can not log into the API page using the guide in the first post, point 2, Ill just get an “undefined” when typing my email and password. However i can log in using the Postman and thru the Node-red code given in another thread here.
Can anyone give me a hint what I am doing wrong?
There is an error in the interactive part of our current API documentation.
But we are days away from releasing a swagger based replacement.
I suggest that you use postman to make the requests instead.
If you find something that is not adequately described in the API documentation, please let us know We are working on improving the documentation all over.
Endpoint elasticsearch and storage/data and 3 are the same, the elasticsearch endpoint was an alias that has since been removed.
The type can be position, accelerometer or primitive.
The key can be rpi-temperature, voltage, coolant_temp, engine_load, fuel_level, fuel_rate, intake_temp or speed.
Those values correspond to a search query in our storage backend, but we have since started migrating to a more generic interface, where the search query is built by the frontend instead, so that you guys can retrieve all your custom data as well.
We are in the process of cleaning up the API, to make it much easier to understand. Like there should not be two different read endpoints.
Sorry about the confusion
The data_type field is used to query in our storage backend. All data that is inserted into our storage system will have an assigned datatype, this datatype will be automatically set to the name of the module that returned the data.
So if you have a module my_module, which has a function called x_value, and you execute that in a job, with the returner set to cloud, then the result will be inserted with a datatype of
my_module.x_value
See 1
Absolutely not, the naming should be consistent. I will see what I can do about that.
The storage/read endpoint returns data from storage, the same as the storage/data endpoint, so I would say yes, but I’m not sure if that’s what you mean by processed data?
All data is logged with the exact timestamp, so they will likely all have slightly different timestamps.
And we currently don’t have a single API call that can return multiple fields, but I expect that the current read endpoint will have that functionality at some point, but due to the slightly different timestamps, this would likely be implemented using aggregations, where the time range is split into smaller groups, and then values in each group is aggregated.
I hope that answers the question, if not, let me know.
We really appreciate all questions and suggestions, and it all helps us prioritize and shape our backlog. I’m sorry about the late reply.

 )! but I dont know how to write same get as postman but in my web page.
)! but I dont know how to write same get as postman but in my web page.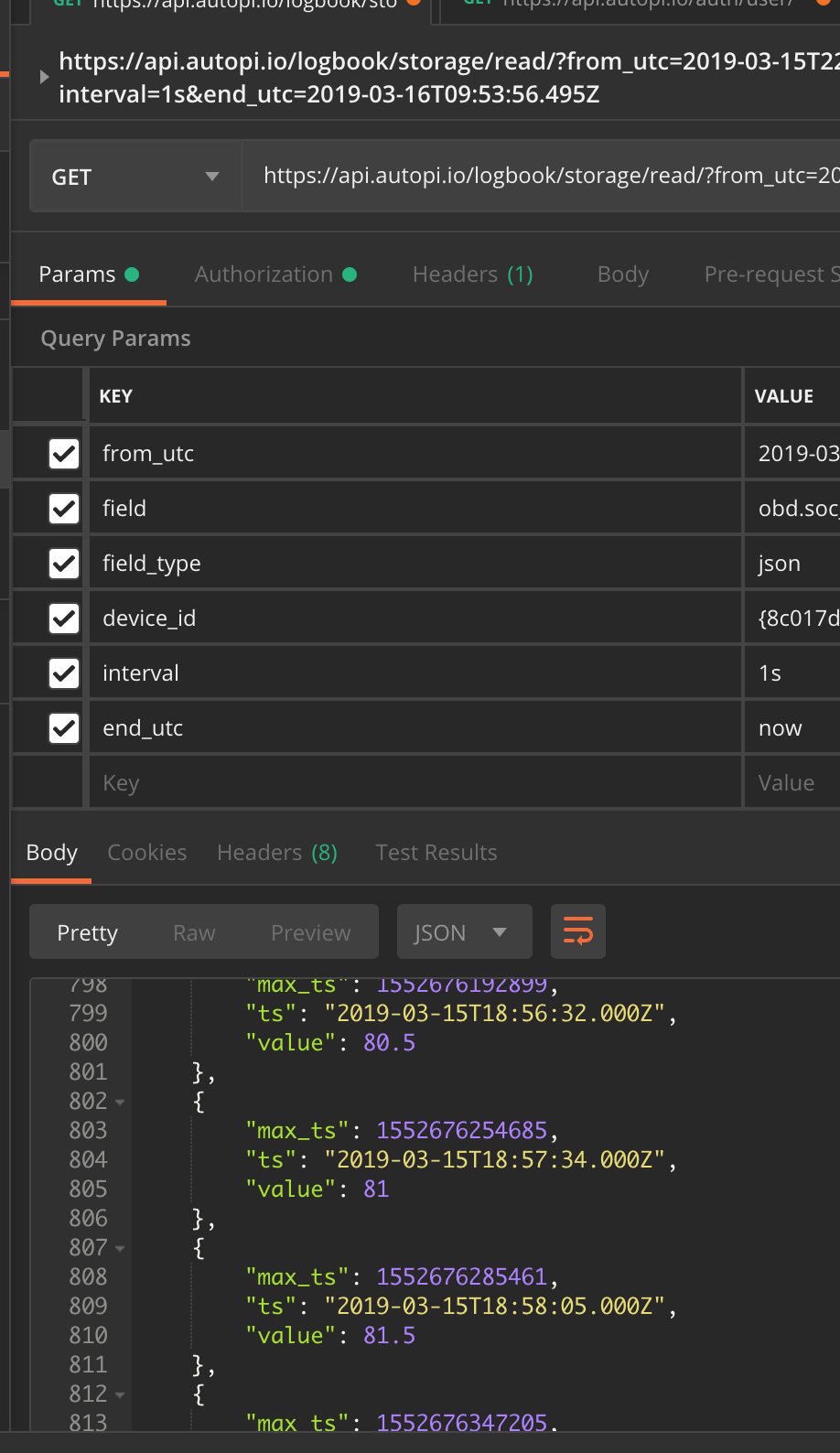
 We are working on improving the documentation all over.
We are working on improving the documentation all over.